Redis集群故障监测及哨兵机制原理解析
Redis海量数据存储方案Redis Cluster
在之前的文章写过redis的实用功能,包括数据结构,主从复制结构,以及应对高并发海量数据场景下的分片redis cluster 集群;本篇文章继续学习redis框架应对缓存失效,以及持久化机制及内存管理出现的问题,以及提供的解决方案及思想。
在redis中缓存失效的原因主要是重启导致数据失效, 解决方案 RDB、AOF持久化机制。以及aof中为什么能保证数据在断电或重启不失效的原因,提供不同的fsync策略:完全没有fsync,每秒fsync,每个查询fsync。使用默认策略fsync时,每秒的写入性能仍然很好(fsync是使用后台线程执行的,并且在没有进行fsync的情况下,主线程将尽力执行写入操作。)保证数据不失效;缓存中常见的内存淘汰与过期管理机制,保证数据更新;以及缓存雪崩分析及解决方案,在redis中利用ehcache 缓存降级,或者Redis备份和快速预热 等都可以避免 缓存出现缓存雪崩问题。
redis中既有RDB持久化,也有AOF持久化,两者是可以并存的。对于数据要求非常高的情况下,官方是推荐使用AOF,在配置文件中使用 redis.conf中对应的开启方式
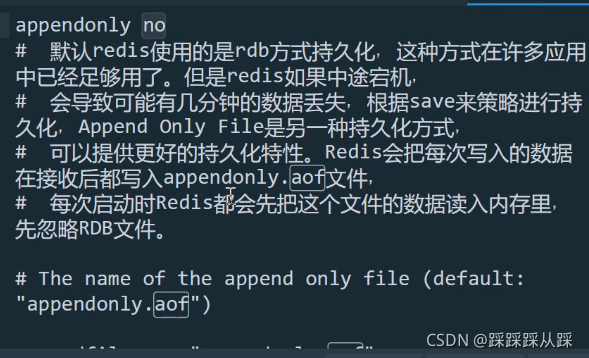
在磁盘中对应的文件名为appendonly.aof
对应rdb与aof的持久化配置策略

RDB 持久化方式能够在指定的时间间隔对你的数据进行快照存储
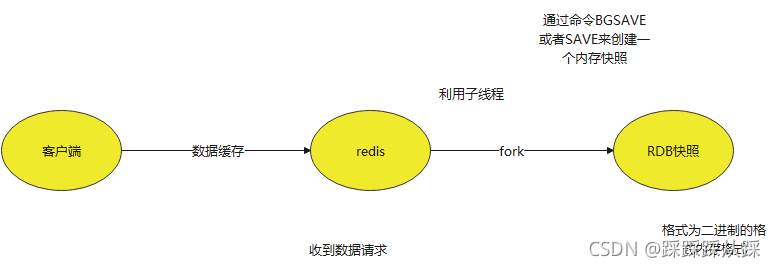
Redis客户端直接通过命令BGSAVE或者SAVE来创建一个内存快照
# 900秒之内至少一次写操作 save 900 1 # 300秒之内至少发生10次写操作 save 300 10 # 60秒之内发生至少10000次 save 60 10000优点
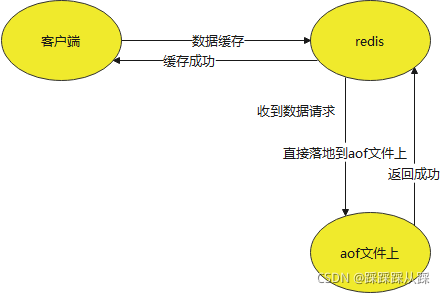
appendonly yes#每次有数据修改发生时都会写入AOF文件,非常安全非常慢 appendfsync always #每秒钟同步一次,该策略为AOF的缺省策略,够快可能会丢失1秒的数据 appendfsync everysec #不主动fsync,由操作系统决定,更快,更不安全的方法 appendfsync no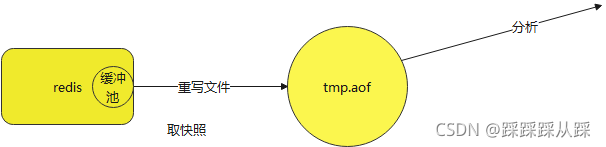
优点
Redis在内存空间不足的时候,为了保证命中率,就会选择一定的数据淘汰策略,这个和我们操作系统中的页面置换算法类似。
# 最大内存控制 maxmemory 最大内存阈值 maxmemory-policy 到达阈值的执行策略
单位是字节 ,利于精确控制
当内存达到配置量时,会做一个内存压缩 ,这些配置都是压缩优化内存手段。
#配置字段最多512个 hash-max-zipmap-entries 512 #配置value最大为64字节 hash-max-zipmap-value 64 #配置元素个数最多512个 list-max-ziplist-entries 512 #配置value最大为64字节 list-max-ziplist-value 64 #配置元素个数最多512个 set-max-intset-entries 512 #配置元素个数最多128个 zset-max-ziplist-entries 128 #配置value最大为64字节 zset-max-ziplist-value 64大小超出压缩范围,溢出后Redis将自动将其转换为正常大小,减少cpu的消耗
Reids的种淘汰策略:
主动处理( redis 主动触发检测key是否过期)每秒执行10次。过程如下:
过期数据的计算和计算机本身的时间是有直接联系的。
配置方式: maxmemory-samples 5结构是通过链表+map来进行实现的,当淘汰也是淘汰链表尾的数据
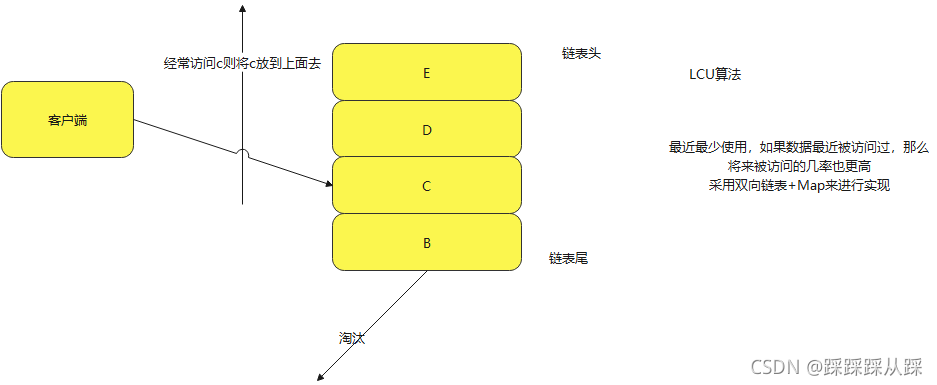
产生的代价就是 访问、删除都需要遍历链表
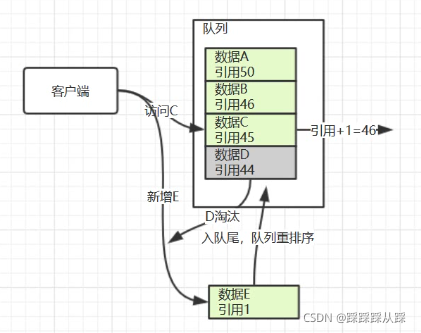
noeviction 客户端尝试执行会让更多内存被使用的命令直接报错 allkeys-lru 在所有key里执行LRU算法 volatile-lru 在所有已经过期的key里执行LRU算法 volatile-lfu 使用过期集在密钥中使用近似LFU进行驱逐 allkeys-lfu 使用近似LFU逐出任何键 allkeys-random 在所有key里随机回收 volatile-random 在已经过期的key里随机回收 volatile-ttl 回收已经过期的key,并且优先回收存活时间(TTL)较短的键
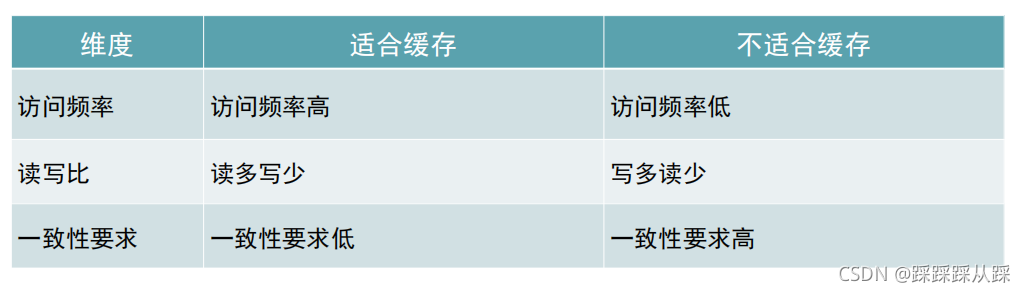
三个维度评判数据是否合适缓存
类似12306网站,因为用户频繁的查询车次信息,假设所有车次信息都建立对应的缓存,那么如果所有车次建立缓存的时间一样,失效时间也一样,那么在缓存失效的这一刻,也就意味着所有车次的缓存都失效。通常当缓存失效的时候我们需要重构缓存,这时所有的车次都将面临重构缓存,即出现问题1的场景,此时数据库就将面临大规模的访问。
春节马上快到了,抢票回家的时刻也快来临了。通常我们会事先选择好一个车次然后疯狂更新车次信息,假设此时这般车的缓存刚好失效,可以想象会有多大的请求会直怼数据库。
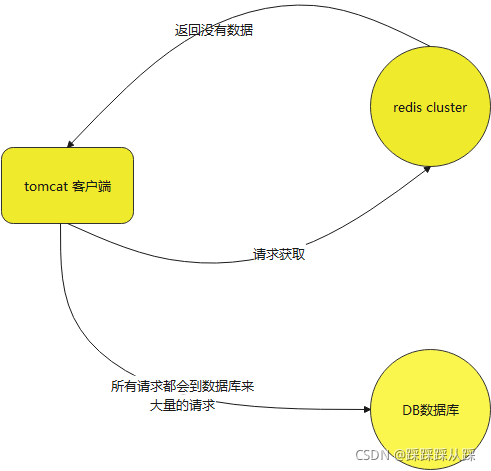
这会造成数据库的压力是非常大的,有可能导致数据库连接占满,有可能会影响其他功能,大量占用数据库连接,导致其他应用访问该DB数据库时,都会等待着,查询慢的情况。这就是缓存雪崩,缓存失效。
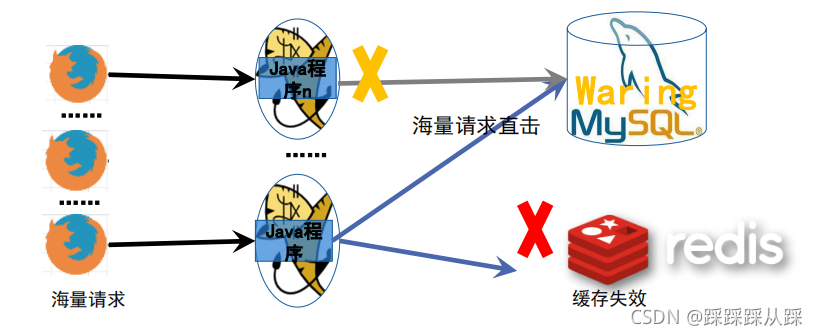
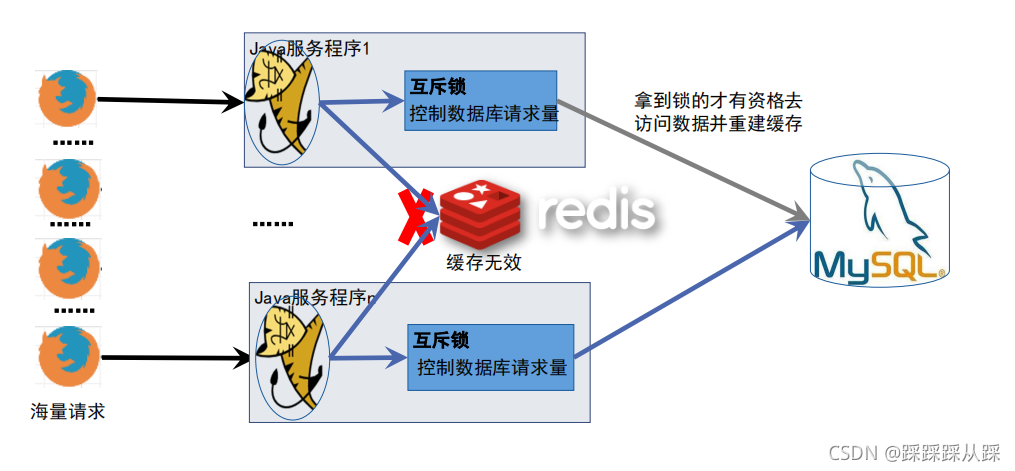
使用锁的机制对商品进行 处理的形式
public class GoodsService2 { private final Logger logger = LoggerFactory.getLogger(GoodsService2.class); @Resource(name = "mainRedisTemplate") StringRedisTemplate mainRedisTemplate; @Autowired DatabaseService databaseService; Lock lock = new ReentrantLock(); /** * 查询商品库存数 * * @param goodsId 商品ID * @return 商品库存数 */ // @Cacheable 不管用什么样的方式,核心步骤 1,2,3 public Object queryStock(final String goodsId) throws InterruptedException { // 1. 先从redis缓存中获取余票信息 String cacheKey = "goodsStock-"+goodsId; String value = mainRedisTemplate.opsForValue().get(cacheKey); if (value != null) { logger.warn(Thread.currentThread().getName() + "缓存中取得数据==============>" + value); return value; } // 2000 请求 // 同步 一个个来 lock.lock(); // 2000 线程 1个线程拿到,1999 等待排队 try { // 再次获取缓存 value = mainRedisTemplate.opsForValue().get(cacheKey); if (value != null) { logger.warn(Thread.currentThread().getName() + "缓存中取得数据==============>" + value); return value; } // 拿到锁 重建缓存 // 2. 缓存中没有,则取数据库 value = databaseService.queryFromDatabase(goodsId); System.out.println(Thread.currentThread().getName() + "从数据库中取得数据==============>" + value); // 3. 塞到缓存,120秒过期时间 final String v = value; mainRedisTemplate.execute((RedisCallback<Boolean>) connection -> { return connection.setEx(cacheKey.getBytes(), 120, v.getBytes()); }); } finally { lock.unlock(); } return value; } }